Deep-Learning: Forsøg på at lære visuelle komponenter i logo-designs
Motivation
Et firmas logo er normalt den første kontakt forbrugeren har med virksomheden, og virksomhedens logo giver derfor et vigtigt indtryk, der former forbrugerens forventninger. At forstå dette indtryk er vigtigt for ledere/virksomheder, når de markedsfører deres brand særligt for nystartede virksomheder, der konkurrerer om forbrugerens opmærksomhed. En nylig undersøgelse fandt, at “… descriptive logos (those that include visual design elements that communicate the type of product) more favorably affect consumers’ brand perceptions than nondescriptive ones.” og det er dermed afgørede at designe et logo, der succesfuldt skildrer den solgte ydelse eller tjeneste i virksomheden.
Design-processen af et nyt logo er normalt en omfattende og udfordrende proces, og ved at bygge bro mellem design og deep learning, håber jeg at kunne bruge et stort datasæt til forstå hemmelighederne bag visuelt design. Målet i studiet er tofoldigt og omfatter:
- Benyt Image Classification til at klassificere den givne branche baseret på logoet.
- Benyt Image Synthesis til at forstå/lære de visuelle komponenter i hver branche.
Hvordan jeg opstillede mine modeller/metoder
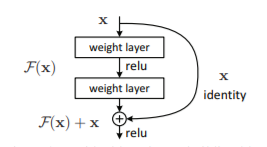
Hele dette studie er bygget op omkring evnen til succefuldt at kunne klassificere den givne branche af en virksomhed baseret på et dens logo. Til at løse denne opgave har jeg benyttet et konventionelt Convolutional Neural Network, mere konkret den efterhånden klassiske arkitektur kaldet ResNet50 (hvor 50 definerer at netværket er bygget op af 50 lag). Det særlige kendetegn ved denne arkitektur er de såkaldte Residual Connections/ Residual Learning Block som kort beskrevet viderefører det givne input for givent lag direkte videre (altså uden at modificere dette input) til næste lag. Dette input lægges derefter til output af det givne lag (hvor input er gået igennem vægt-lag og ReLU activation). Nedenfor er arkitekturen af denne Residual Learning Block illustreret:
Transfer Learning
Efter arkitekturen af mit klassificerings-netværk var besluttet, benyttede jeg mig af Transfer Learning, som i alt sin enkelthed går ud på at genbruge vægte i netværket som allerede er trænet på et andet datasæt. Dette gøres primært for at reducere træningstiden af netværket (eller hvis man har et lille datasæt). I mit tilfælde downloadede jeg vægte som var Pre-Trained på det velkendte ImageNet dataset, hvorefter jeg brugte Fine-Tuning til at tilpasse vægtene til mit aktuelle logo-datasæt. (For mere information om data-sættet: https://arxiv.org/abs/1911.07924).
Træning af netværket
Før den egentlige træning af netværket påbegyndte, eksperimenterede jeg med forskellige HyperParameters såsom træningens Learning Rate, Batch-size samt forskellige optimeringsalgoritmer (og HyperParameters i den forbindelse). Med de tilgængelige ressourcer lykkedes det mig at træne netværket omkring 18 epoker. Træningen belv udført på den gratis GPU tilgængeligt på Google Colaboratory, hvor 1 epoke tog omkring 1 time. Resultatet af denne træning kan ses nedenfor:

Efter endt træning opnåede jeg en test-accuracy på 57,91% på test-datasættet som modellen ikke har set før. En accuracy på omkring 60% er, sammenlignet med andre billede-klassificerings opgaver, ret lav. Den primære årsag til dette skal findes i manglende ressourcer til at færdiggøre træningen, som af ovenstående plot ikke tyder på at være konvergeret. Derudover er der en række udfordringer i data-sættet og hypotesen om at kunne bestemme en virksomheds branche baseret på dens logo (der kan findes en mere dybdegående diskussion af dette i den fulde artikel).
Image Synthesis til at forstå/lære de visuelle komponenter i hver branche
Med et trænet billede-klassificerings netværk kunne jeg begynde at forstå/lære de visuelle komponenter der dominerede hver branche. Her benyttede jeg en metode indenfor Image Synthesis kaldet Activation Maximization. Dette er en visualiserings-metode som oprindeligt er brugt til at visualisere og forstå neuronerne i et Convolutional Neural Network. Metoden går ud på at generere et kunstigt input-billede (her et logo), som aktiverer en given neouron/lag mest muligt i netværket. I mit tilfælde var målet at generere et kunstigt billede/logo som ville maksimere scoren i et af netværkets valgte output-neuroner. I mit tilfæde var der 10 output neuroner (en fra hver branche), hvor brugen af en Softmax Activation Function gør, at scoren i disse neuroner kan betragtes som sandsynligheden for, at det givne input billede tilhører en pågældende branche. Sagt med andre ord er målet at generere et logo, som maksimerer sandsynligheden for at dette logo eksempelvis tilhører medicinal-branchen. Dette kan formuleres matematisk med følgende optimeringsproblem:
![\[x^* = \underset{x}{\text{arg max}}\bigg(a_i(x)-R_\theta(x)\bigg) \]](https://usercontent.one/wp/www.skipconnect.dk/wp-content/ql-cache/quicklatex.com-562232919557b03d55c365430c7d9006_l3.png?media=1642085122 "Rendered by QuickLaTeX.com")
Hvor  er en parametriseret regulerings funktion som skal prøve at sikre at billederne der dannes har billede lignende egenskaber. At vælge denne funktion og tilhørende parametre er en stor udfordring for at generere billeder, som giver indsigt. (For en nærmere diskussion af valget af denne/disse funktioner/parametere og deres indflydelse på billedet se da den fulde artikel). Nedenfor ses et eksempel på forskellige genererede billeder som alle har til formål at maksimere sandsynligheden for at tilhøre medicinal-branchen.
er en parametriseret regulerings funktion som skal prøve at sikre at billederne der dannes har billede lignende egenskaber. At vælge denne funktion og tilhørende parametre er en stor udfordring for at generere billeder, som giver indsigt. (For en nærmere diskussion af valget af denne/disse funktioner/parametere og deres indflydelse på billedet se da den fulde artikel). Nedenfor ses et eksempel på forskellige genererede billeder som alle har til formål at maksimere sandsynligheden for at tilhøre medicinal-branchen.

Af ovenstående er det meget svært at få et indblik/indsigt i nogle dominerende visuelle komponenter som skulle dominere logoer i medicinal-branchen. Den største udfordring med metoden benyttet ovenfor er, at der er stor variabilitet af loger indenfor samme branche, hvilket gør det derfor svært at skulle fange alle disse forskelligheder i samme billede/ samme metode. Til at imødekomme denne udfordring udviklede Anh Mai Nguyen et al. (2016) en algoritme som ville generere et “start-billede” til Activation Maximization metoden og således starte optimeringsproblemet herfra. Denne metode/algortime til at finde “start-billedet” er illustreret i nedenstående figur:

Selvom denne metode har vist tydelig forbedring i andre domæner, så havde denne ikke den store indvirkning på mine resultater. Nedenfor er der vist et eksempel på de 15 logoer, der var tættest på to vilkårligt udvalgte klynger efter kørsel af K-Means, samt det tilhørende “start-billede” og resultatet af de kunstigt genererede billeder.

De to oventående metoder har begge én fælles stor udfordring. I begge tilfælde er billedernes kvalitet meget afhængig af den parametriseret regulerings funktion , hvor de valgte parametere er fundet ved Random-Search som er ressource-tungt og garenterer ikke den bedste løsning. Til at imødekomme denne udfordring benyttede jeg en tredje metode, som i stedet for at optimere i et høj-dimensionelt rum (et billede) i stedet maksimerer i et lav-dimensionelt “latent-space“. For at opnå dette trænede jeg et Generative Adversarial Network (GAN) på mit data-sæt, som består af både en Generator og Descriminator, hvor efter endt træning Generatoren blev benyttet til at kunne maksimere i et lav-dimensionelt “latent-space“. Metoden og processen er illustreret i nedenstående diagram:

Resultatet af denne metode er illustreret nedenfor:

Ovenstående resultat giver (som de andre metoder) ikke værdifuld indsigt i de visuelle komponenter der dominerer de forskellige loger i forskellige brancher. Grundet ressourcemæssige begrænsninger var det kun muligt at træne GAN netværket i 3 epoker, og viste ingen tegn på være konvergeret. Dette er stor årsag til at ovenstående resultat er mangelfuldt.
Diskussion / Konklusion
Som også nævnt i artiklen ovenfor, så opnåede jeg ikke de ønskede resultater i dette projekt. Det var meget svært at sige noget omkring de visuelle komponenter, der dominerer forkellige brancher. De primære årsager til, at resultaterne ikke var som ønsket er:
- Det er en svær opgave at klassificere en virksomheds branche ud fra dens logo, selv for os mennesker. (Hypotesen om at logoer i samme brancher deler mange af de samme visuelle komponenter kan være falsk/ ikke tydelig nok)
- Begrænsede ressourcer har gjort at modellerne/netværkerne ikke er trænet tilstrækkeligt. Alle billede-genererings metoderne afhænger af klassificerings-netværket som opnåede en relativ lav accuracy (~60%).
For den interessede læser er der en mere dybdegående diskussion i den fulde artikel, hvor også kvaliteten af data-sættet bliver diskuteret. Her bliver metoderne som er nævnt ovenfor også beskrevet mere detaljeret. Desuden er det muligt at finde koden til projektet og den fulde implementering på min GitHub.